Continuous Integration - Build
三种分支模式
-
稳定主线
项目中只有一条稳定主线,所有开发人员的代码都直接提交到该主线上,包括新features,bug fix 等。项目Release时不开新分支,只给主线上打上tag进行标记。
该模式的最大好处就是管理方便,分支零成本管理,不涉及多分支间的合并问题。也是Martin Fowler同学推荐的模式。
该模式带来的问题是如果团队规模较大(20人+),构建时间较长时,开发人员提交代码的频率会降低,也会降低开发人员提交代码的积极性。
-
稳定分支
项目中有一条稳定主线,该主线只进行新features开发。项目Release时拉新分支作为发布分支。发布分支相对stable,不做新特性开发,只进行hot fixes.
该模式比较适合传统软件的开发,例如freebsd 只有一条主线current,所有的新features都在该主线上发布,等到主线的特性积累到一定的milestone时,再从主干分出一个stable分支。
如果新功能已经集成在主干上,但是达不到发布的要求,那么稳定分支就不能创建,这会影响到下一个发布计划。并且所有在stable上做的hot fixes最终都要合并到主干上来。
-
活跃分支-稳定主线-稳定分支
项目中除了一条稳定主线与若干条稳定分支外,还存在有一条或多条活跃分支,该类型分支的建立通常有两方面原因:
- 项目中开发人员人员较多时,会出现稳定主线模式所带来的问题。此时按照feature等拉出新的活跃分支时,可以使相关开发人员的集成关注点更加明确,也能提高他们提交代码的积极性。比如CWP项目中的Proxy feature最初就是在新分支上进行构建,每天早上由指定人员来与主干进行合并。
- 有时项目中可能会有一些改动的影响面较大,并且需要较长时间。但是这些改动同时具有原子性,即或者全部改动生效,或者全部改动都需要进行回滚。例如CWP项目中的new branding 特性就属于这类情况。该特性需要对所有页面进行布局重构,影响面很大,最初的做法是将改动直接提交到主干上,但是发现经常会break 集成测试。因此对该特性也拉出一条活跃分支,使其独立工作在活跃分支上。最后在改动全部完成后,将其所有代码合并回主干。
这种模式所带来的最大问题就是代码合并,因为随着分支数量的增加,意味着每条分支所作的修改最终可能都需要合并到主干上。
构建
Martin Fowler指出一次完整的构建应该包括如下七个步骤:
- 将已集成的源代码复制一份到本地计算机。
- 修改产品代码和添加修改自动化测试。
- 在自己的计算机上启动一个自动化构建。
- 构建成功后,把别人的修改更新到我的工作拷贝中。
- 再重新做构建。
- 把修改提交到源码仓库。
- 在集成计算机上并基于主线的代码再做一次构建。

其中第5步操作会要求锁住主线代码,不允许其他人在这个时间段再次提交。
在讨论有哪些步骤可以省略的过程时,我首先想到的是省略本地构建过程,这里包含了两个假设:
- 主线必须是长绿的,表示随时可以发布,项目发展健康。并且只有在主线绿的时候才能更新代码。
- 第4步更新下来的代码无论如何都是需要本地构建的。而此时构建出的错误也必须是构建者来修理。
因此,无论有没有第3步构建,4,5两步都是要做的,而且错误发生在本地,还必须由构建者来处理。因此这样看来第3步似乎有些多余。那么第3步的价值究竟体现在哪里呢?个人觉得是在于出错后的反馈时间较快,并且能较为容易的定位到问题。
换一种思路,如果省掉的不是步骤3,而是步骤5会怎么样?这也可以从几个方面来分析:
- 本地自己写的代码质量是由第3步构建保证的,而第5步之所以可能出错,原因也一定是由合并代码导致的。但是这种错误出现的几率较小,可以考虑忽略。
- 如果省略了第5步,就不会导致主线在该阶段被锁,这样有助于提升构建效率。
- 主线是要保证健康的,但是健康状态一定是由长绿来保证么?我觉得未必,健康不代表不会出错,而是应该关注出错后的修复时间,如果主线构建出错,但是只需要很少的时间便能修复。那么把第5步的构建过程推迟到第7步去做,即使构建出错,也问题不大。
构建问题:
构建时间长:
每次构建需要较长时间,已经超出团队的容忍限度。解决方式通常包括几个方面:
- 分析原因。构建脚本做了太多没用的事情?构建流程是否应该改进等等。
- 并行构建。一般通过增加硬件机器来进行。这也是一种见效最快的方案。
- 低成本测试。将项目中花费时间较长的测试改为时间较短的测试,通常可以尽可能多的将功能(集成)测试的验证通过做单元测试来覆盖。数据库相关的测试改为内存相关等等。但是这同时也会带来一些负面影响,比如降低了测试的可信度。
- 分阶段或者减少无用测试。通常可以将测试划分为快和慢两种情况,针对速度较快的测试,可以在每次构建的时候都运行,而对于速度较慢但相对稳定的测试,可以选择分时段运行。
环境不一致:
构建的环境与产品实际运行环境不一致。通常包括几个方面:
- 操作系统不一致。比如开发用windows,构建用linux。而实际产品可能跨平台。解决方法是采用多种平台进行构建。
- 测试工具不一致。通常为开发环境下用的测试工具和集成环境下用的测试工具上的差异。
- 设置不一致。包括权限设置不一致、环境变量设置不一致、文件系统不一致等等。
- 数据不一致。比如测试用的数据都是些固定简单的fixtures,而产品环境下的数据较为复杂。虽然每次构建都是通过的,但是没能暴露出问题。这也可以归朔回构建不可信的原因。
强行提交:
构建尚未通过,其他人就已经开始提交。这类问题的解决方法是提交前进行检查,如果上次提交未通过,那么先revert上次提交的代码,直到待提交分支通过后再提交本地改动代码。
构建报告的通知方式:
包括email,SMS,音乐,熔岩灯,显示器等。
报告的分析:
结合工具从横向(不同人,不同团队之间)与纵向(团队自身的过去与现在)将数据以趋势和对比的形式展示出来.
参考文献:http://www.infoq.com/cn/articles/ci-theory-practice 肖鹏
Continuous Integration - Why need it?
Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily - leading to multiple integrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible. Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive software more rapidly. This article is a quick overview of Continuous Integration summarizing the technique and its current usage. -- Martin Fowler
开场用老马的话来引入持续集成的概念。作为一个系列Camp,首先介绍下为什么需要持续集成。
为什么需要持续集成:
在传统软件(瀑布模型)公司做过开发的朋友应该都清楚,软件开发的流程大致分为:
需求定义——系统分析——概要设计——详细设计——编码——测试——部署
等几个步骤。一般情况下只有再软件测试完毕后客户才能拿到自己“想要”的产品。而这里面却隐含了两个问题:
首先,什么时候软件才能测试完毕?这个通常随着项目的周期长短而不同,或者若干个月,或者一年半载甚至更长。也就是说,只有在用户提出需求后的很长时间后,他们才能看到软件。
其次,数月后产生的东西真的是用户“想要”的产品吗?未必,或者更极端说一定不可能。这可以从两个方面进行解释。
-
不同人多相同事物的理解是不一致的。即便充分沟通后,也有可能对一些概念产生曲解。比如在结对编程中有一种Drive-Watch的模式,这通常在一个经验相对丰富的人和一个经验相对较少的人pair时采用。通常人们都会将该模式理解为经验丰富的人来Drive(写代码),经验较少的人来Watch(观察学习)。其实不然。事实上Drive-Watch对象指的都是经验丰富的那个人,而他主要负责指点新人编程,而不是代码都由他来写。类似于这种被称为common sense的概念如果开始时就被曲解,而没有提前发现,就很有可能在今后逐步积累成更大的错误。同理,软件开发过程也是一样的。如果我们开始对需求的理解有就错误(事实上不可能没有错误),尤其是一些概念的理解偏差,而这种错误没有及时暴露出来,后续很多功能又都是基于该概念的。那么最后出来的软件质量可想而知。
- 人对事物的理解是渐进的。在面对一个庞大而复杂的系统时,人脑很难对它有一个完整且清晰的认识。客户提需求也是一样,软件交付之所以困难,其中很大一部分原因就是因为需求的不断变化。而这种变化是贯穿在整个软件开发过程中,或者说,需求变化本身就是软件开发过程的组成部分。当采用瀑布模型开发时,这种变化也只能在数月甚至数年后测试结束时才能反映出来。
相信做过传统软件开发的朋友,在这两点上都或多或少的被瀑布模型刺痛过。那么有没有一种开发模式能解决上述问题呢?答案当然是肯定的——持续集成。
开始持续集成:
定义
从狭义上来说,持续集成是指持续集成工具,市场上包括Hudson,Cruise,Go等,该类型工具可以监听代码库的改动(ChangeSet),并且根据预定义的脚本来执行测试、构造等活动。以达到快速反馈的目的。
从广义上来说,持续集成就是敏捷开发,它不仅有上面提到的狭义定义,还贯穿整个软件的开发流程,包括团队组织模式,Story划分,Pair Programming,TDD,重构,代码集成策略,以及部署等等。
版本控制系统(VCS)的比较与选择
现在市面主流的版本控制系统包括SVN, Mercurial Hg,Git,ClearCase,VSS等等。
Hg与Git 属于分布式版本控制系统(DVCS),适合分布式团队开发。同时他们会在本地存一份完整的Repository,因此提交速度也相对较快。支持多人同时修改同一个文件(需要手工或自动Merge)。
SVN的Repository在远程,因此提交代码或者查看文件修改历史时会相对较慢。也支持多人同时修改同一文件。
ClearCase与VSS的Repository在远程,修改的提交是基于文件而非ChangeSet,因此提交速度最慢。并且不支持多人同时修改同一文件。
在代码所有制为集体的前提下,推荐使用SVN或者HG/GIT。这两类工具可以更好的提升团队的开发效率。
Make Watir Support Jquery event
I have been in use watir(1.8.0) and ruby(1.8.7) for Regression test recently. I've got a problem yesterday. Look the demonstration page below:
<html>
<head>
<script src="http://code.jquery.com/jquery.min.js" type="text/javascript"></script>
</head>
<body>
<select id ="s1">
<option value="1">123</option>
<option value="2">456</option>
<option value="3">789</option>
</select>
<script>
$('#s1').change(function(){
alert('fired');
});
</script>
</body>
</html>
when I use the code below to hope fire the change event of select element,but it can't work.
require "watir"
@browser = Watir::Browser.new
@browser.goto('a.html')
@browser.select_list(:id, 's1').set('456')
I deep in to the source code of watir(1.8.0),and found the code that:
def select_item_in_select_list(attribute, value) #:nodoc:
assert_exists
highlight(:set)
found = false
value = value.to_s unless [Regexp, String].any? { |e| value.kind_of? e }
@container.log "Setting box #{@o.name} to #{attribute.inspect} => #{value.inspect}"
@o.each do |option| # items in the list
if value.matches(option.invoke(attribute.to_s))
if option.selected
found = true
break
else
option.selected = true
@o.fireEvent("onChange")
@container.wait
found = true
break
end
end
end
unless found
raise NoValueFoundException, "No option with #{attribute.inspect} of #{value.inspect} in this select element"
end
highlight(:clear)
end
As the code show,Watir calling API of win32ole object,and raise the native event "onChange".but this couldn't fire "change" event which jquery support. It's so tricky!
After a research in google.i got this answer from StackOverFlow.
@browser = Watir::Browser.new
@browser.goto("http://someurl")
@browser.select_list(:id, element_id).select(item_to_select)
@browser.ie.Document.parentWindow.execScript('$("##{element_id}").change();')
it's really cool method and seems resolved my problem(Let's say WATIR SUCKS loudly ). I couldn't use this directly because this is just a demonstration.In production environment,there are a lot of same invoke.To avoid duplication code,i have to extend watir to support our requirement.
......................
............
option.selected = true
@o.fireEvent("onChange")
script = %Q{$("##{self.id}").change();}
@o.Document.parentWindow.execScript(script)
@container.wait
found = true
break
.............
................
It works well now!
File input element can not work well in IE with Watir 1.8.0 and Ruby187
最近一段时间一直在和同事张逸做项目(Web)相关的regression test,使用的是cucumber(0.10.2)与watir (1.8.0)。总体来讲还算是不错(Ruby开发效率高),但昨天在做文件上传(file upload)相关的测试时,发现了watir的一个问题。代码如下:
def file index
@browser.file_field(:index => index)
end
def fill_file_with_index file_name,index
file_full_path = get_file_full_path(file_name)
on(UploadDocumentsPage) do
file(index).set(file_full_path)
end
end
函数file定义了UploadDocumentsPage中按照index去查询type为 file类型的dom元素。fill_file_with_index 定义了按照索引(index)找到指定的file元素,并且该元素设置相应值(file_name)。功能很简单,但是在实际运行过程中发现页面在弹出choose file to upload对话框后,并没有去设置相应的文件路径,而是就hold在那里不运行了。简单调试了下发现是卡在了set(file_full_path)这句上。Google未果,于是跟进watir中相应源码:
def set(path_to_file)
assert_exists
require 'watir/windowhelper'
WindowHelper.check_autoit_installed
begin
Thread.new do
sleep 10 # it takes some time for popup to appear
system %{ruby -e '
require "win32ole"
@autoit = WIN32OLE.new("AutoItX3.Control")
time = Time.now
while (Time.now - time) < 15 # the loop will wait up to 15 seconds for popup to appear
#{POPUP_TITLES.inspect}.each do |popup_title|
next unless @autoit.WinWait(popup_title, "", 1) == 1
@autoit.ControlSetText(popup_title, "", "Edit1", #{path_to_file.inspect})
@autoit.ControlSend(popup_title, "", "Button2", "{ENTER}")
exit
end # each
end # while
'}
end.join(1)
rescue
raise Watir::Exception::WatirException, "Problem accessing Choose file dialog"
end
click
end
end
该方法主要逻辑是:
- 首先检查是否安装了AutoIt(用来模拟鼠标键盘操作的工具),如果没有,抛异常结束。
- 如果有安装,则新开启一个线程,并休眠当前线程10秒(等待pop up对话框),然后使用system 去执行一条命令,该命令在15秒内不断的去轮询标题为“Choose File to Upload”的窗体,一旦找到该窗体,就会自动为该窗体设置相应的值(path_to_file),并调用回车键(Enter)。
- 调用click(弹出Choose File to Upload对话框)
逻辑似乎没有什么问题,但运行起来为什么会出现问题呢?经过无数次puts测试,我们发现问题出现在新线程的sleep 10 # it takes some time for popup to appear 这一句上。当主线程pop up window出现后,新线程的sleep就再也醒不来了….尼玛这是为什么呢?我猜应该是Ruby187的bug。
找到问题后,解决方案也就很容易了,可以自己简单模拟sleep的实现:
def fake_sleep expected_time time_start = Time.now time_end = time_start while(time_end - time_start < expected_time) time_end = Time.now end end
把源码中的sleep 10 替换成fake_sleep 10,跑测试,问题依旧…继续分析发现问题出在join(1)上,先看下join函数的说明:
The calling thread will suspend execution and run <i>thr</i>. Does not
return until <i>thr</i> exits or until <i>limit</i> seconds have passed. If
the time limit expires, <code>nil</code> will be returned, otherwise
<i>thr</i> is returned.
原来新线程执行join(1)后会在1s后会立即返回,而此时线程的sleep 10 还没有结束,后面的代码也就没有机会去执行了…
最终我们修改源码如下:
def set(path_to_file)
assert_exists
require 'watir/windowhelper'
WindowHelper.check_autoit_installed
begin
Thread.new do
system %{ruby -e '
require "win32ole"
@autoit = WIN32OLE.new("AutoItX3.Control")
time = Time.now
sleep 2
while (Time.now - time) < 15 # the loop will wait up to 15 seconds for popup to appear
#{POPUP_TITLES.inspect}.each do |popup_title|
next if @autoit.WinWait(popup_title, "", 1) == 0
@autoit.ControlSetText(popup_title, "", "Edit1", #{path_to_file.inspect})
@autoit.ControlSend(popup_title, "", "Button2", "{ENTER}")
exit
end # each
end # while
'}
end.join(1)
rescue
raise Watir::Exception::WatirException, "Problem accessing Choose file dialog"
end
click
end
end
测试通过!
Mars Rover In Ruby
最近用业余时间学习了ruby,拜服于ruby语言与其他静态语言不同的各类奇淫邪技……
为了验证下自己的学习质量,就用ruby把很久前用其他语言做过的一道Mars Rover题目又重新做了一遍。
代码及题目描述已经放到了这里:http://code.google.com/p/mars-rover-in-ruby/
有兴趣的同学也可以做做,欢迎交流!
看见测试变绿后居然很兴奋..... TDD伤不起啊 
虽然是用ruby写的,但是代码及设计风格还是按照之前写c# code的风格,没有真正的 on ruby way。这也是纠结的地方……
One way to design Message model
在一般的企业级应用中,Message是一个很常见的应用,其主要目的是可以让系统内的用户(包括系统用户)可以交流(包括attachment)。
如何去设计一个Message BE(Business Model)模型?
首先会想到一种简单的做法:
class Message attr_accessor(:subject, :content, :readDate,:sender,:isReaded,:recipients,:attachments) end
这种做法的好处就是简单明了,将所有信息全部都放在了Message 上,检索数据的SQL语句也会写的比较简单。但是这样的设计在系统使用一段时间就会发现系统的performance越来越差!究其原因,是因为每条Message在发出去时都会复制给所有的recipients,造成Message entity膨胀过快,导致performance 降低。
那我们改进的方法就是要避免message的过度增长,分析上面的模型,我们发现如果将isReaded、readDate和recipients抽成一个新entity,似乎就可以避免Message的复制。如下图示:
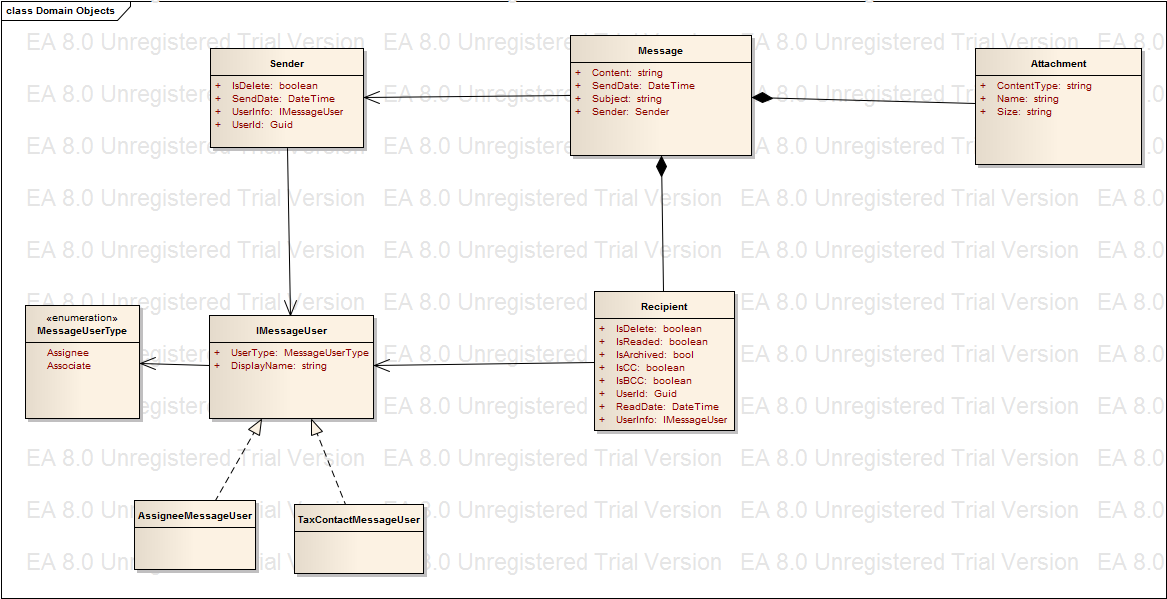
其中Recipient 中存储消息的接收人,这样在s1发送一条消息M发给r1,r2.r3时,只会产生如下Entity:
One Sender,
One Message,
Three Recipient
(其他entity可以暂时忽略掉)
如果sender或者recipient 要删除自己的message时,只需要将自身相应的IsDeleted设置为true即可(想想为什么不能直接删除entity?:)
模型的主要设计思路到此为止。
关于当前项目中出现的一些特殊需求,比如:
Kayla给自己的tax contact发的消息应该自动被kayla所属client的所有tax contacts共享。
这个其实只需要在发送邮件时自动bcc给其他tax contacts 就OK了。
Tell Me.Don't Ask!
先看一个简单的例子,假设有这样一种场景:我们需要比较有一个有大小和单位的Length对象的相等性。
通常会这样做:
1、定义Length对象.
public class Length
{
public int Value { get; private set; }
public Unit Unit { get; private set; }
public Length(int count, Unit unit)
{
Value = count;
Unit = unit;
}
}
其中Unit是一个表示单位的Enum
2.override Equal 方法.
public override bool Equals(object obj)
{
if (obj is Length)
{
var length = obj as Length;
if (IsEqual(length)) return true;
}
return false;
}
private bool IsEqual(Length thatLength)
{
var thatBaseLength = ConvertFactory.ConvertToBaseUnit(thatLength);
var thisBaseLength = ConvertFactory.ConvertToBaseUnit(this);
return thatBaseLength.Value == thisBaseLength.Value;
}
其中ConvertFactory的作用是把当前/待比较Length对象转换成一个基准单位(Unit)的Length对象工场。来看实现:
public class ConvertFactory
{
private ConvertFactory(){}
public static Length ConvertToBaseUnit(Length length)
{
IConvert convert = null;
if (length.Unit == Unit.M)
{
convert = new MConvertToCM();
}
if(length.Unit == Unit.DM)
{
convert = new DMConvertToCM();
}
...................
return convert.ConvertToBase(length);
}
}
代码很清晰的告诉了我们单位是M或者DM的Length对象都将会被转换成为单位是M的对象。随便看一个MConvertToCM的实现:
public class MConvertToCM : IConvert
{
public Length ConvertToBase(Length length)
{
return new Length(length.Value*100, Unit.CM);
}
}
很好,完毕了。我们不仅实现了场景的功能,而且还在其中使用了多种OO技术与设计模式。似乎做的很完美(至少我第一次写出这样的代码时是这种感觉:)
但是,让我们再回头看看Length对象,两个属性都是public getter,
-------------Q&A------------------------------
为什么要公开这两个属性呢?因为我们在MConvertToCM里会用到啊!
为什么非要在MConvertToCM里用这两个属性?.......我们就这样设计的啊!
为什么要这样设计?........无语了
-------------Q&A------------------------------
好吧,问题似乎陷入了僵局,为什么我们非要把自己的属性直接暴露给其他对象?我们如果不这样做又可以有什么办法达到将自身的数据传递给其他对象呢?
文章中提到如果将一个对象的数据暴露出来的目的是为了在外部改变这个对象的数据/行为的做法是不合适的。
回到我们这个场景来看,Value与Unit公开的目的是为了在构建另一个自己,看清楚了这点,后面的操作也就变得比较容易了。直接上代码
public interface LengthAndUnitAction
{
void action(int value, Unit unit);
}
public class Length
{
private int Value { get; set; }
private Unit Unit { get; set; }
public Length(int count, Unit unit)
{
Value = count;
Unit = unit;
}
.......................
public void Execute(LengthAndUnitAction action)
{
action.action(Value, Unit);
}
}
我们把行为单独抽成一个接口,然后让Length类再调用接口的同时将内部属性传递出去。这样Value/Unit就可以变为私有变量,从而更好的起到了数据封装的作用。
Let's refactor it-OpenSinaAPI
这两天一直在看Clean Code以及 重构,一直想找一些例子练练手。恰巧前两天在玩新浪微博应用的时候看到了陈着写的这个SDK。down下来代码后发现这里面还有很多可以重构的地方,于是花了一个周末实践了一下。
在简单了解了下OAuth的原理及使用后,先确定了重构的范围:
1、基础类oAuthBase.cs不动,因为这个类是由官方提供的。
2、有必要时外部调用接口也需要更改(事实上写到最后几乎对所有的接口都改了)。
开始下手,先看oAuthWebRequest这个函数
public string oAuthWebRequest(Method method, string url, string postData)
{
string outUrl = "";
string querystring = "";
string ret = "";
postData += "&source=" + appKey;
if (method == Method.POST)
{
if (postData.Length > 0)
{
NameValueCollection qs = HttpUtility.ParseQueryString(postData);
postData = "";
foreach (string key in qs.AllKeys)
{
if (postData.Length > 0)
{
postData += "&";
}
qs[key] = HttpUtility.UrlEncode(qs[key]);
qs[key] = this.UrlEncode(qs[key]);
postData += (key + "=" + qs[key]);
}
if (url.IndexOf("?") > 0)
{
url += "&";
}
else
{
url += "?";
}
url += postData;
}
}
Uri uri = new Uri(url);
string nonce = this.GenerateNonce();
string timeStamp = this.GenerateTimeStamp();
//Generate Signature
string sig = this.GenerateSignature(uri,
this.appKey,
this.appSecret,
this.token,
this.tokenSecret,
method.ToString(),
timeStamp,
nonce,
out outUrl,
out querystring);
querystring += "&oauth_signature=" + HttpUtility.UrlEncode(sig);
if (method == Method.POST)
{
postData = querystring;
querystring = "";
}
if (querystring.Length > 0)
{
outUrl += "?";
}
if (method == Method.POST || method == Method.GET)
ret = _WebRequest(method, outUrl + querystring, postData);
return ret;
}
这个函数的目的是来创建请求,并且将请求结果返回。
让我们来识别一下这个函数都有哪些bad smell:
1、long method.这个方法足足有70行。
2、Temporary Field.光函数开头声明的临时变量就有3个,函数内部声明的临时变量更是不尽其数。
3、Single Responsibility Principle.函数中充斥着大量的if-else,以及多处判断POST与Get。
4、Higher Cyclomatic Complexity.函数中存在可以避免的嵌套 if-else
重构的方法:
首先根据不同的请求类型(POST/GET)来声明不同的处理方法,为了使客户类调用行为一致,我这里抽取出了一个IHttpRequestMethod接口
public interface IHttpRequestMethod
{
string Request(string uri, string postData);
}
其中Request方法相当于原库中oAuthWebRequest,分别用两个类HttpGet与HttpPost来实现。
然后是将这个方法拆解成为几个小方法。最后的代码如下:
public class HttpPost : BaseHttpRequest
{
.....
......
public override string Request(string uri, string postData)
{
var appendUrl = AppendPostDataToUrl(postData, uri);
string outUrl;
var querystring= AppendSignatureString(POST, appendUrl, out outUrl);
return WebRequest(POST, outUrl, querystring);
}
......
}
public class HttpGet : BaseHttpRequest
{
.......
......
public override string Request(string uri, string postData)
{
string outUrl;
var queryString = AppendSignatureString(GET, uri, out outUrl);
if (queryString.Length > 0)
{
outUrl += "?";
}
return WebRequest(GET, outUrl + queryString);
}
......
}
全部代码参见:
http://code.google.com/p/opensinaapi/downloads/detail?name=OpenSinaApi04-18-2011.rar
欢迎各位看官一起动手来进一步重构:)